Non-Exadata Architecture:-
Exadata - SmartScan
EXADATA SERVER SQL PROCESSING
With Exadata storage, SQL processing is handled much more efficiently because it uses Exadata storage software, which has database logic built into it. The following steps comprise Exadata SQL processing, as shown in the following diagram
1. A client submits a query.
2. The database server constructs an Intelligent Database (iDB) message, which includes the query criteria. This iDB message goes to all storage servers in a rack.
3. The cellsrv component of the ESS scans the data blocks to identify the matching rows and columns that satisfy the request.
4. Every storage server executes the query criteria in parallel and sends only the relevant rows, or the net result, to the database server by using interconnect.
5. The database consolidates the result and returns the rows to the client.
The iDB (Intelligent Database) protocol is a custom protocol used in Oracle Exadata for communication between the database servers and the storage cells.
It facilitates Smart I/O operations, allowing the storage cells to perform tasks like Smart Scan (SQL offload) and Fast File Initialization, thereby improving performance and reducing data transfer.
Here's a more detailed explanation:
iDB Protocol:
This protocol is an InfiniBand-aware network protocol designed by Oracle, implemented on Reliable Datagram Sockets V3. It's used for communication between the database servers (where the Oracle Database and ASM processes reside) and the storage cells (where the Exadata Storage Server software resides).
Functionality:
iDB messages are used to direct Smart I/O operations on the storage servers. This includes Smart Scan, which offloads portions of SQL queries to the storage servers, and Fast File Initialization, which optimizes initial data loading.
Smart I/O:
Exadata leverages iDB to offload I/O-intensive tasks to the storage servers, reducing the amount of data that needs to be transferred between the database servers and storage.
Performance Benefits:
By performing certain operations on the storage servers, Exadata can significantly improve performance, especially for analytical workloads and large datasets.
Implementation:
iDB is implemented in the database kernel and maps database operations to Exadata-enhanced operations, making it transparent to the user.
Underlying Technology:
iDB uses the high-speed InfiniBand network fabric (or RDMA over Converged Ethernet/RoCE) to transmit data between the database servers and storage cells, ensuring efficient and low-latency communication.
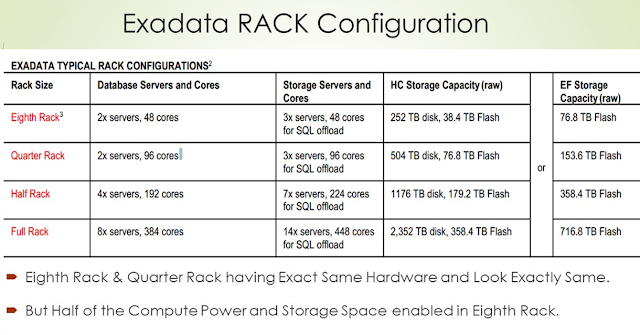
High Capacity( HC) and Extreme Flash (EF)
Smart Scan/Cell Offloading:
Smart Scan or Cell offloading is the feature where the Database offload
all resource consuming operations like Selecting the particular dataset (or)
backup operations to its storage nodes instead of performing on DB Nodes.
Consider if you are querying employee table having terabytes of data and you just requested only a few records out of it..
In Traditional systems, the terabytes of data fetched from OS and DB Resources like DB Buffer Cache, Temp Segments and Server resources like CPU, Memory used to filter out the required data. Due to this, the other DB and OS Operations face a huge wait time.
In Exadata, the DB Node pass the SQL Operation to Storage Nodes through IDB.
The Storage server perform smart scan on the requested data and Return only the requested Query Output (or) the Requested blocks to the database that is just a few records.
DB node just get the data and pass it to User.
As all these operations happening on Storage node which is higher Capacity,
the performance impact is nearly zero even for complex query operations.
Hybrid Columnar Compression (HCC)
HCC is an unique compression algorithm which groups column data and compress them.
Traditionally, the Rows are stored directly on the blocks and if we compress,
only the unused bytes of the blocks will get compressed.
In Hybrid Columnar compression, a set of rows grouped under Compression Unit based
on the column data and get compressed.
For Ex. on the employee table, eventhough we have 1M records, the Department column might have a
few unique values.
So HCC will create a master data for the values and create only points to rest of the rows.
Through this we can achieve 10x to 15x Compression ratio which will reduce the IO operations and Storage requirements.
Storage Indexes..
The Storage Indexes are created on the Storage servers which is built
based on the queries and data being requested.
The Storage Indexes having min and Max Values of every block data and
it will help the storage servers to reach the appropriate block to get the required data.
Storage Index is not status and wiped out during Storage node reboot and
Start Caching again automatically.
The query must undergo Full Table Scan to enable the feature of Storage Indexes.
This eliminates the need for DB indexes and its maintenance.
Smart Flash Cache..
Every Storage Server provided with 4 Flash Cards which makes the Flash Cache..
The Flash Cache is similar to DB Buffer Cache, where it stores the frequently
used data which is beyond size of DB Buffer cache in its Flash memory.
So that the storage server need not to fetch the data from Disks.
As reading from Flash is much faster, The exadata storage server can perform 4M IO operation per second which is so enormous.
Now we have Frequently used data is available on Flash Cache. If not, we can use Smart Scan too.
Resource Manager (IORM/DBRM)
Now the storage server scanning only needed blocks using smart scan and
the data compressed using HCC and we can able to point the data directly using Storage Indexes.
Also the frequently used data is available on Flash Cache.
All these are features are used to reduce the IOPS and IO Wait times to improve performance.
But how do i prioritize if my app and batch users running queries on the database at the same time…
That is the Purpose of Resource Manager in Exadata.
Resource Manager in storage server works based on IORM and its functionality similar
to DB Resource Manager (DBRM) and work with DBRM to prioritize the query on Storage Nodes.




















No comments:
Post a Comment