Optimizer statistics are a collection of data that describe the database and the objects in it. The optimizer uses these statistics to choose the best execution plan for each SQL statement. Being able to gather the appropriate statistics in a timely manner is critical to maintaining acceptable performance on any Oracle system. With each new release, Oracle strives to provide the necessary statistics automatically.
A summary is presented here, but full details can be found in Reference 1, Understanding Optimizer Statistics with Oracle Database 19c.
High-frequency Automatic Statistics Gathering
This Oracle Database 19c new feature is available on certain Oracle Database platforms. Check the Oracle Database Licensing Guide for more information.
Stale statistics can mislead the optimizer and in some cases can result in a sub-optimal plan. To address this, automatic optimizer statistics collection was introduced in Oracle 11g. The automated maintenance task infrastructure schedules statistics gathering to occur in maintenance windows. By default, one window is scheduled for each day of the week and statistics collection runs in all predefined maintenance windows.
For systems with rapidly changing datasets, data can drastically change in a short period time, rapidly rendering statistics stale and making daily statistics gathering insufficient.
New to Oracle Database 19c, high-frequency automatic statistics collection is introduced as a complement to the existing auto task. It is decoupled from the maintenance window. By configuring the DBMS_STATS preferences, the DBA can customize the frequency and maximum run time according to their requirement. Note that the existing automatic statistics collection running in the predefined maintenance window will not be affected, and high-frequency automatic statistics task will not start during the maintenance window.
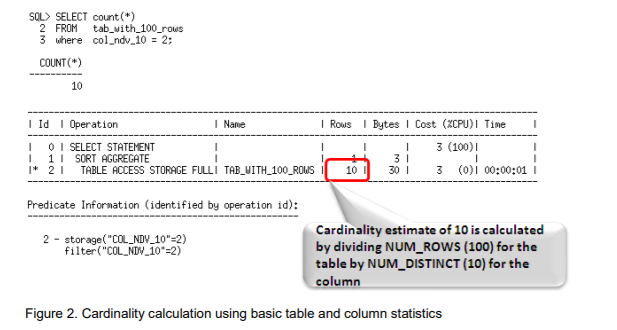
Histograms
Histograms tell the optimizer about the distribution of data within a column. By default, the optimizer assumes a uniform distribution of rows across the distinct values in a column and will calculate the cardinality for a query with an equality predicate by dividing the total number of rows in the table by the number of distinct values in the column used in the equality predicate. The presence of a histogram changes the formula used by the optimizer to determine the cardinality estimate, and allows it to generate a more accurate estimate.
Online Statistics Gathering
When an index is created, Oracle automatically gathers optimizer statistics as part of the index creation by piggybacking the statistics gather on the full data scan and sort necessary for the index creation (this has been available since Oracle Database 9i). The same technique is applied for direct path operations such as, create table as select (CTAS) and insert as select (IAS) operations into empty tables. Piggybacking the statistics gather as part of the data loading operation, means no additional full data scan is required to have statistics available immediately after the data is loaded. The additional time spent on gathering statistics is small compared to a separate statistics collection process, and it guarantees to have accurate statistics readily available from the get-go.
Real-time Statistics
This Oracle Database 19c new feature is available on certain Oracle Database platforms. Check the Oracle Database Licensing Guide for more information.
Online statistics gathering for create table as select (CTAS) and direct path insert was first introduced in Oracle Database 12c Release 1. This allows statistics to be accurate and available immediately, but prior to Oracle Database 19c, this capability was not applicable to conventional database manipulation language (DML) operations which dominate the way data is manipulated in (for example) traditional OLTP systems.
Real-time statistics extends the online statistic gathering techniques to conventional insert, update and merge DML operations. In order to minimize the performance overhead of generating these statistics, only the most essential optimizer statistics are gathered during DML operations. The collection of the remaining stats (such as the number of distinct values) is deferred to the automatic statistics gathering job, high-frequency stats gathering and/or the manual invocation of the DBMS_STATS API. See Reference 2, Best Practices for Gathering Optimizer Statistics with Oracle Database 19c, for more information.
Incremental Statistics
Gathering statistics on partitioned tables consists of gathering statistics at both the table level (global statistics) and at the (sub)partition level. If data in (sub)partitions is changed in any way, or if partitions are added or removed, then the global-level statistics must be updated to reflect the changes so that there is correspondence between the partition-level and global-level statistics. For large partitioned tables, it can be very costly to scan the whole table to reconstruct accurate global-level statistics. For this reason, incremental statistics were introduced in Oracle Database 11g to address this issue, whereby synopses were created for each partition in the table. These data structures can be used to derive global-level statistics – including non-aggregatable statistics such as column cardinality - without scanning the entire table.
Incremental Statistics and Staleness
A DBMS_STATS preference called INCREMENTAL_STALENESS allows you to control when partition statistics will be considered stale and not good enough to generate global level statistics. By default, INCREMENTAL_STALENESS is set to NULL, which means partition level statistics are considered stale as soon as a single row changes (the same behavior as in Oracle Database 11g). Alternatively, it can be set to USE_STALE_PERCENT or USE_LOCKED_STATS. USE_STALE_PERCENT means the partition level statistics will be used as long as the percentage of rows changed (in the respective partition or subpartition) is less than the value of the preference STALE_PERCENTAGE (10% by default). USE_LOCKED_STATS means if statistics on a partition are locked, they will be used to generate global level statistics regardless of how many rows have changed in that partition since statistics were last gathered.
Incremental Statistics and Partition Exchange Loads
One of the benefits of partitioning is the ability to load data quickly and easily, with minimal impact on the business users, by using the exchange partition command. The exchange partition command allows the data in a non-partitioned table to be swapped into a specified partition in the partitioned table. The command does not physically move data; instead it updates the data dictionary to exchange a pointer from the partition to the table and vice versa.
The Oracle Database allows you to create the necessary statistics (synopses) on load tables before they are exchanged into the partitioned table. This means that global partition statistics can be maintained incrementally the moment that the load table is exchanged with the relevant table partition.
Compact Synopses
The performance for statistics gathering with incremental statistics can come with the price of high disk storage of synopses (they are stored in the SYSAUX tablespace). More storage is required for synopses for tables with a high number of partitions and a large number of columns, particularly where the number of distinct values (NDV) is high. Besides consuming storage space, the performance overhead of maintaining very large synopses can become significant. Oracle Database 12c Release 2 introduced a new algorithm for gathering and storing NDV information, which results in much smaller synopses while maintaining a similar level of accuracy to the previous algorithm.
CONCURRENT STATISTICS
When the global statistics gathering preference CONCURRENT is set, Oracle employs the Oracle Job Scheduler to create and manage one statistics gathering job per object (tables and / or partitions) concurrently.
AUTOMATIC COLUMN GROUP DETECTION
Extended statistics were introduced in Oracle Database 11g. They help the optimizer improve the accuracy of cardinality estimates for SQL statements that contain predicates involving a function wrapped column (e.g. UPPER(LastName)) or multiple columns from the same table that are used in filter predicates, join conditions, or group-by keys. Although extended statistics are extremely useful it can be difficult to know which extended statistics should be created if you are not familiar with an application or data set.
Auto column group detection, automatically determines which column groups are required for a table based on a given workload. The detection and creation of column groups is a simple three-step procedure3.
NEW REPORTING SUBPROGRAMS IN DBMS_STATS PACKAGE
Knowing when and how to gather statistics in a timely manner is critical to maintain acceptable performance on any system. Determining what statistics gathering operations are currently executing in an environment and how changes to the statistics methodology will impact the system can be difficult and time consuming.
Reporting subprograms in DBMS_STATS package make it easier to monitor what statistics gathering activities are currently going on and what impact changes to the parameter settings of these operations will have. The DBMS_STATS subprograms are REPORT_STATS_OPERATIONS, REPORT_SINGLE_STATS_OPERATION and REPORT_GATHER_*_STATS.
Figure 18 shows an example output from the REPORT_STATS_OPERATIONS function. The report shows detailed information about what statistics gathering operations have occurred, during a specified time window. It gives details on when each operation occurred, its status, and the number of objects covered and it can be displayed in either text or HTML format.