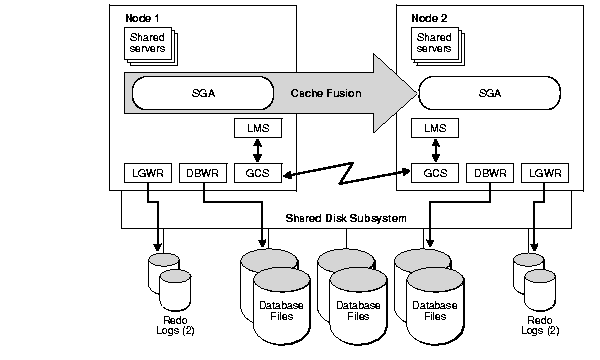
An Oracle RAC database has the same processes and memory structures as a single-instance Oracle database and additional process and memory structures that are specific to Oracle RAC. The global cache service and global enqueue service processes, and the global resource directory (GRD) collaborate to enable cache fusion. The Oracle RAC processes and their identifiers are as follows:
ACMS
Atomic Control File to Memory Service
GTX[0-j]
Global Transaction Process
LMON
Global Enqueue Service Monitor-Lock Monitor
LMD
Global Enqueue Service Daemon
LMS
Global Cache Service Process
LCK0
Instance Enqueue Process
LMHB
Global Cache/Enqueue Service Heartbeat Monitor
PING
Interconnect Latency Measurement Process
RCBG
Result Cache Background Process
RMSn
Oracle RAC Management Processes
RSMN
Remote Slave Monitor
above figure illustrates how GCS works with GES to maintain GRD
RAC Background Processes
Each node has its own background processes and memory structures, there are additional processes than the norm to manage the shared resources, theses additional processes maintain cache coherency across the nodes.
Cache coherency is the technique of keeping multiple copies of a buffer consistent between different Oracle instances on different nodes. Global cache management ensures that access to a master copy of a data block in one buffer cache is coordinated with the copy of the block in another buffer cache.
The sequence of a operation would go as below
When instance A needs a block of data to modify, it reads the bock from disk, before reading it must inform the GCS (DLM). GCS keeps track of the lock status of the data block by keeping an exclusive lock on it on behalf of instance A
Now instance B wants to modify that same data block, it to must inform GCS, GCS will then request instance A to release the lock, thus GCS ensures that instance B gets the latest version of the data block (including instance A modifications) and then exclusively locks it on instance B behalf.
At any one point in time, only one instance has the current copy of the block, thus keeping the integrity of the block.
GCS maintains data coherency and coordination by keeping track of all lock status of each block that can be read/written to by any nodes in the RAC.
GCS is an in memory database that contains information about current locks on blocks and instances waiting to acquire locks. This is known asParallel Cache Management (PCM).
The Global Resource Manager (GRM) helps to coordinate and communicate the lock requests from Oracle processes between instances in the RAC.
Each instance has a buffer cache in its SGA, to ensure that each RAC instance obtains the block that it needs to satisfy a query or transaction.
RAC uses two processes the GCS and GES which maintain records of lock status of each data file and each cached block using a GRD.
So what is a resource, it is an identifiable entity, it basically has a name or a reference, it can be a area in memory, a disk file or an abstract entity.
A resource can be owned or locked in various states (exclusive or shared). Any shared resource is lockable and if it is not shared no access conflict will occur.
A global resource is a resource that is visible to all the nodes within the cluster.
Data buffer cache blocks are the most obvious and most heavily global resource, transaction enqueue's and database data structures are other examples.
GCS handle data buffer cache blocks and GES handle all the non-data block resources.
All caches in the SGA are either global or local, dictionary and buffer caches are global, large and java pool buffer caches are local.
Cache fusion is used to read the data buffer cache from another instance instead of getting the block from disk, thus cache fusion moves current copies of data blocks between instances (hence why you need a fast private network), GCS manages the block transfers between the instances.
Finally we get to the processes
Oracle RAC Daemons and Processes
LMSn
Lock Manager Server process - GCS
1) This is the cache fusion part and the most active process,
2) The LMS process maintains records of the data file statuses and each cached block by recording information in the GRD.
3) The Primary job of LMS process is to transport blocks across the nodes.
4) For example if a node requests consistent-read of a block, The LMS process makes a Consistent-Read image of the block from another node with the help of undo segments and then transports the blocks through the network to the node who requested it.
5) The LMS process also controls the flow of messages to remote instances and manages global data block access and transmits block images between the buffer caches of different instances.
6) It handles the consistent copies of blocks that are transferred between instances.
7) It receives requests from LMD to perform lock requests.
8) It rolls back any uncommitted transactions.
9) There can be up to ten LMS processes running and can be started dynamically if demand requires it.
10) They manage lock manager service requests for GCS resources and send them to a service queue to be handled by the LMSn process.
11) It also handles global deadlock detection and monitors for lock conversion timeouts.
12) As a performance gain you can increase this process priority to make sure CPU starvation does not occur.
13) You can see the statistics of this daemon by looking at the view X$KJMSDP
LMON
Lock Monitor Process - GES
1) LMON is responsible for monitoring all instances in a cluster for the detection of failed instances.
2) Once a failed Instance is detected it facilitates in the recovery of global locks held by that instance.
3) It is also responsible for reconfiguration of locks and other resources when instances leave or are added to the cluster.
4) This dynamic reconfiguration is done in real-time.
5) This process manages the GES, it maintains consistency of GCS memory structure in case of process death.
6) It is also responsible for cluster reconfiguration and locks reconfiguration (node joining or leaving),
7) It checks for instance deaths and listens for local messaging.
8) The LMON monitors the entire cluster to manage the global enqueues and the resources and performs global enqueue recovery operations.
9) LMON manages instance and process failures and the associated recovery for the Global Cache Service (GCS) and Global Enqueue Service (GES).
10) In particular, LMON handles the part of recovery associated with global resources.
11) LMON provided services are also known as cluster group services (CGS).
12) Lock monitor manages global locks and resources.
13) It handles the redistribution of instance locks whenever instances are started or shutdown.
14) Lock monitor also recovers instance lock information prior to the instance recovery process.
15) Lock monitor co-ordinates with the Process Monitor (PMON) to recover dead processes that hold instance locks.
16) LMON taking care the registration of database instance with the node monitoring part of the cluster(CSSD).
17) LMON detects the instance transitions and performs reconfiguration of GES and GCS resources.
18) A detailed log file is created that tracks any reconfigurations that have happened.
LMD
Lock Manager Daemon - GES
1) The LMD process basically acts as a broker to LMS process by sending requests for resources to a queue that is handled by the LMS process.
2) These requests are placed by the global cache service in order to keep the block buffers consistent across all the instances.
3) The other responsibility of LMD is of detection and resolution of global deadlocks, along with monitoring of lock timeouts in the global environment.
4) This manages the enqueue manager service requests for the GCS.
5) It also handles deadlock detention and remote resource requests from other instances.
6) You can see the statistics of this daemon by looking at the view X$KJMDDP
7) The LMD process manages incoming remote resource requests within each instance.
8) The LMD is the lock agent process that manages enqueue manager service requests for Global Cache Service enqueues to control access to global enqueues and resources.
9) This process manages incoming remote resource requests within each instance.
10) The LMD process also handles deadlock detection and remote enqueue requests.
11) Remote resource requests are the requests originating from another instance.
12) LMDn processes manage instance locks that are used to share resources between instances.
13) LMDn processes also handle deadlock detection and remote lock requests.
LCK0
Lock Process - GES
1) The LCK process is similar to LMD process, but it handles requests for all global resources excluding requests for database block buffers.
2) Manages instance resource requests and cross-instance call operations for shared resources.
3) It builds a list of invalid lock elements and validates lock elements during recovery.
4) The LCK0 process manages noncache fusion resource requests such as library and row cache requests.
DIAG
Diagnostic Daemon
1) It regularly monitors the health of the instance.
2) Checks for instance hangs and deadlocks.
3) It captures diagnostic data for instance and process failures.
4) This is a lightweight process, it uses the DIAG framework to monitor the health of the cluster.
5) It captures information for later diagnosis in the event of failures.
6) It will perform any necessary recovery if an operational hang is detected.
Instance Enqueue Process (LCK0): The LCK0 process manages noncache fusion resource requests such as library and row cache requests.
Global Cache/Enqueue Service Heartbeat Monitor (LMHB): LMHB monitors LMON, LMD, and LMSn processes to ensure they are running normally without blocking or spinning.
Interconnect Latency Measurement Process (PING): Every few seconds, the process in one instance sends messages to each instance. The message is received by PING on the target instance. The time for the round trip is measured and collected.
Result Cache Background Process (RCBG): This process is used for handling invalidation and other messages generated by server processes attached to other instances in Oracle RAC.
Oracle RAC Management Processes (RMSn): The RMSn processes perform manageability tasks for Oracle RAC. Tasks accomplished by an RMSn process include creation of resources related to Oracle RAC when new instances are added to the clusters.
Remote Slave Monitor (RSMN): The RSMN process manages background slave process creation and communication on remote instances. These background slave processes perform tasks on behalf of a coordinating process running in another instance.
Oracle RAC is composed of two or more instances. Oracle RAC Cache Fusion is mechanism to transfer data blocks from the one instance’s buffer cache to another instance’s buffer cache across the cluster interconnect. When a block of data is read from disk by an instance within the cluster and another instance is in need of the same block, it is easy to get the block image from the instance which has the block in its SGA rather than reading from the disk. Transfers across this private network are in order of magnitude better than disk I/O activity and they help Oracle RAC performance.
Cache Fusion Ships Blocks from Cache to Cache Across the Interconnect:
Buffer Cache, Shared Pool and the Undo Tablespace like single-instance database are required to facilitate the Cache Fusion. But Extra coordination is needed in the cluster to make a collection of instances work together.
Before explained how Cache Fusion works, We will know –
Global Resource Directory (GRD): On RAC, GRD process keeps track of the resources in the cluster. There is no true concept of a master node in Oracle RAC but each instance of cluster can becomes the resources mater.
Track master instances of all buffers.
GRD is present on all the instances of the cluster.
How to find the master node for a resource in RAC:
SQL> SELECT DATA_OBJECT_ID, OBJECT_ID FROM DBA_OBJECTS
WHERE OBJECT_NAME = 'TBL_CFUSION';
DATA_OBJECT_ID OBJECT_ID
-------------- ----------
93836 93836
SQL> SELECT b.dbablk, r.kjblmaster master_node
FROM x$le l, x$kjbl r, x$bh b
WHERE b.le_addr = l.le_addr and l.le_kjbl = r.kjbllockp and b.obj = &Data_Object_ID;
Enter value for data_object_id: 93836
old 3: WHERE b.obj = &Data_Object_ID and b.le_addr = l.le_addr and l.le_kjbl = r.kjbllockp
new 3: WHERE b.obj = 93836 and b.le_addr = l.le_addr and l.le_kjbl = r.kjbllockp
DBABLK MASTER_NODE
---------- -----------
225 1
230 1
227 1
224 1
229 1
226 1
231 1
228 1
8 rows selected.
Global Cache Services (GCS): Global Cache Services are responsible to transfer blocks from one instance to another. A single-instance database relies on enqueues (locks) to protect for modifying the same records by two processes simultaneously. Buffer Cache on all instances appear to be global and enqueues on the resources is also global across the cluster.
LMS – LMS is a GCS process. This process used to called the Lock Manager Server.
#Use the following syntax to query V$SYSSTAT:
SQL> SELECT NAME,VALUE FROM V$SYSSTAT WHERE NAME LIKE '%global cache%';
SQL>
Global Enqueue Services (GES): Global Enqueue Services is responsible for managing locks across the cluster. GES was previously called the Distributed/Dynamic Lock Manager (DLM).
Holds the information on the locks on the buffers.
Each lock has a name shown in V$LOCK_ELEMENT (or X$LE).
If a buffer is locked, the lock element name is shown in V$BH.LOCK_ELEMENT.
SQL> UPDATE SAMAD.TBL_CFUSION SET NAME='Y' WHERE ID=4;
Note::: MODE_HELD : Platform dependent value for lock mode held; often: 3 = share; 5 = exclusive
How GES Workloads Affect Performance:
Calculate the ratio of local-to-remote global enqueue resource operations using this query:
SELECT
r.CONVERT_TYPE,
SUM(r.AVERAGE_CONVERT_TIME),
SUM(l.AVERAGE_CONVERT_TIME),
SUM(r.CONVERT_COUNT),
SUM(l.CONVERT_COUNT)
FROM V$GES_CONVERT_LOCAL l, V$GES_CONVERT_REMOTE r
WHERE r.convert_count <> 0 OR l.convert_count <> 0
GROUP BY r.CONVERT_TYPE;
LMON: LMON process is the GES master process. LMD – Lock Manager Daemon. This process manages incoming lock requests. LCK0 – The instance enqueue process. This process manages lock requests for library Cache objects.
How Cache Fusion Works:
How Oracle RAC read block from disk or buffer of other Instance using Cache Fusion?
Object is not available on Buffer. See the output from V$BH.
1st time run select query – SELECT ID FROM SAMAD.TBL_CFUSION
Collect sql_trace of the query and generate TKPROF report.
Node 1:
When we run any query in database first time or blocks are not available in cache then all blocks read from database file for rac and stand alone database.
SQL> SELECT DATA_OBJECT_ID, OBJECT_ID FROM DBA_OBJECTS
WHERE OBJECT_NAME = 'TBL_CFUSION';
DATA_OBJECT_ID OBJECT_ID
-------------- ----------
9383693836
SQL> @obj_buffer.sql
Enter value for objid: 93836
old 21: WHERE OBJD= &OBJID
new21: WHERE OBJD= 93836
no rows selected
SQL> ALTER SESSION SET SQL_TRACE = TRUE;
Session altered.
SQL> SELECT ID FROM SAMAD.TBL_CFUSION;
ID
----------
1
1
4
3
SQL> ALTER SESSION SET SQL_TRACE = FALSE;
Session altered.
TKPROF output. There are 6 IOs from disk of this query.
There is no physical IO for the query execution even object was not in Buffer cache. Means all required blocks for this object retrieved from 1st Instance buffer cache instead of Disk.
444 TABLE ACCESS FULL TBL_CFUSION(cr=8 pr=0 pw=0 time=1263 us cost=3 size=12 card=4)
How Oracle RAC maintain blocks in buffer across the cluster for DML?
When a block is requested by user:
The buffer cache is searched on local buffer cache
If not found, there are two options
Get from the other cache across the cluster
Get from disk
If found on buffer on other instance, there are three options:
Send the buffer to the user
Examine other caches for the presence of this buffer
Get from the disk
How does it decide which option to take?
The buffer can be retrieved in two modes
Consistent Read (CR) -> Block contains uncommitted changes. Session will get a version of the block prior to the changes. Intention to read block
Current -> If intention to modify
There can be several CR copies of a buffer
There can be only one current mode
For an instance
Each current buffer is Shared Current
Only one buffer in the entire cluster can be Exclusive Current
SQL> show user
USER is "SAMAD"
SQL> Create Table SAMAD.TBL_CFTEST(id number, name char(2000));
insert into SAMAD.TBL_CFTEST Values(1, 'Samad');
insert into SAMAD.TBL_CFTEST Values(2, 'Samad');
insert into SAMAD.TBL_CFTEST Values(3, 'Samad');
insert into SAMAD.TBL_CFTEST Values(4, 'Samad');
Table created.
SQL> SQL>
1 row created.
SQL> SQL>
1 row created.
SQL> SQL>
1 row created.
SQL> SQL>
1 row created.
SQL> commit;
Commit complete.
SQL> SELECT EXTENT_ID, BLOCK_ID, BLOCKS FROM DBA_EXTENTS
WHERE SEGMENT_NAME = 'TBL_CFTEST';
EXTENT_ID BLOCK_ID BLOCKS
---------- ---------- ----------
0 232 8
SQL> SELECT ID,
DBMS_ROWID.ROWID_RELATIVE_FNO(ROWID) FILE#,
DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID) BLOCK#
FROM SAMAD.TBL_CFTEST;
ID FILE# BLOCK#
---------- ---------- ----------
1 6 238
2 6 238
3 6 238
4 6 239
SQL> SELECT DATA_OBJECT_ID, OBJECT_ID FROM DBA_OBJECTS
WHERE OBJECT_NAME = 'TBL_CFTEST';
DATA_OBJECT_ID OBJECT_ID
-------------- ----------
93861 93861
For DML, rows on block status is xcur (exclusive current) and these are most recent current copy of block. xcur status for a rows is possible a copy on an instance across the cluster.
SQL> @obj_buffer.sql
Enter value for data_obj_id: 93861
old 9: where objd = &data_obj_id
new 9: where objd = 93861
FILE# BLOCK# CLASS_TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 232 1st level bmb xcur 00000000877DADA0
6 233 2nd level bmb xcur 00000000877E5958
6 234 segment header xcur 0000000087BF7C48
6 235 data block xcur 0000000087BEED00
6 236 data block xcur 00000000877D96A8
6 237 data block xcur 00000000877DBF20
6 238 data block xcur 00000000877E7C58
6 239 data block xcur 00000000877E4490
8 rows selected.
Node 2:
SQL> SELECT DATA_OBJECT_ID, OBJECT_ID FROM DBA_OBJECTS
WHERE OBJECT_NAME = 'TBL_CFTEST';
DATA_OBJECT_ID OBJECT_ID
-------------- ----------
93861 93861
TBL_CFTEST object is not available in buffer cache on local instance. When run the select command of this table,
SQL> @obj_buffer.sql
Enter value for objid: 93861
old 21: WHERE OBJD= &OBJID
new 21: WHERE OBJD= 93861
no rows selected
SQL> SELECT INSTANCE_NUMBER FROM V$INSTANCE;
INSTANCE_NUMBER
---------------
2
SQL> SELECT ID FROM SAMAD.TBL_CFTEST WHERE ID = &ID;
Enter value for id: 1
old 1: SELECT ID FROM SAMAD.TBL_CFTEST WHERE ID = &ID
new 1: SELECT ID FROM SAMAD.TBL_CFTEST WHERE ID = 1
ID
----------
1
These blocks are available in Node 1 which is resource master.
SQL> select b.dbablk, r.kjblmaster master_node
from x$le l, x$kjbl r, x$bh b
where b.le_addr = l.le_addr
and l.le_kjbl = r.kjbllockp and b.obj = &DataObjectId; 2 3 4
Enter value for dataobjectid: 93861
old 4: and l.le_kjbl = r.kjbllockp and b.obj = &DataObjectId
new 4: and l.le_kjbl = r.kjbllockp and b.obj = 93861
DBABLK MASTER_NODE
---------- -----------
238 1
235 1
237 1
234 1
239 1
236 1
6 rows selected.
Selected only one record and it should return the relevant block (block # 238) and it copied all blocks as there was no index and it reads all block for full table scan.
When oracle cache fusion request a block for reading from another instance, block copies as Consistence Read (CR) mode from other instance then cope the same block as scur mode. Oracle remain CR mode block because that point user request to read these block. SCUR (Shared Current) means these rows are up to date for across the cluster and Oracle can rely this row for any further changes in cluster.
In this point on node 2, have two copies of the blocks.
SQL> @obj_buffer.sql
Enter value for objid: 93861
old 21: WHERE OBJD= &OBJID
new 21: WHERE OBJD= 93861
FILE# BLOCK# CLASS TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 234 SEGMENT HEADER cr 00
6 234 SEGMENT HEADER scur 00000000803FA178
6 235 DATA BLOCK scur 00000000803F1230
6 235 DATA BLOCK cr 00
6 236 DATA BLOCK scur 0000000087BE01D8
6 236 DATA BLOCK cr 00
6 237 DATA BLOCK scur 0000000087BE4D50
6 237 DATA BLOCK cr 00
6 238 DATA BLOCK cr 00
6 238 DATA BLOCK scur 0000000087BE6448
6 239 DATA BLOCK cr 00
FILE# BLOCK# CLASS TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 239 DATA BLOCK scur 0000000087BE00C0
12 rows selected.
Now on Node 1, rows status changed from xcur to scur means these block’s most recent copies are available in another nodes. in this case, we saw that these blocks copies to node 2 as scur. If we have any rows status xcur means these are exclusively current across the cluster.
XCUR and SCUR both mode for a row in buffer is not possible at the same time.
SCUR on both nodes means Oracle will consider any one instance for these rows as these are up to date on both nodes.
SQL> @obj_buffer.sql
Enter value for data_obj_id: 93861
old 9: where objd = &data_obj_id
new 9: where objd = 93861
FILE# BLOCK# CLASS_TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 234 segment header scur 0000000087BF7C48
6 235 data block scur 0000000087BEED00
6 236 data block scur 00000000877D96A8
6 237 data block scur 00000000877DBF20
6 238 data block scur 00000000877E7C58
6 239 data block scur 00000000877E4490
8 rows selected.
Now try to update a row on Instance 1, and we see that row status has been changed to xcur and also remain with CR copy for read consistence.
SQL> UPDATE SAMAD.TBL_CFTEST SET NAME='Y' WHERE ID=2;
1 row updated.
SQL> @obj_buffer.sql
Enter value for data_obj_id: 93861
old 9: where objd = &data_obj_id
new 9: where objd = 93861
FILE# BLOCK# CLASS_TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 238 data block xcur 00000000877E7C58
6 238 data block cr 00
6 239 data block scur 00000000877E4490
3 rows selected.
Now on Node 2, Now we got two cr copies for block# 238 and no scur copy as we had xcur on Node 1.
SQL> @obj_buffer.sql
Enter value for objid: 93861
old 21: WHERE OBJD= &OBJID
new 21: WHERE OBJD= 93861
FILE# BLOCK# CLASS TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 238 DATA BLOCK cr 00
6 238 DATA BLOCK cr 00
6 239 DATA BLOCK cr 00
6 239 DATA BLOCK scur 0000000087BE00C0
4 rows selected.
SQL> SELECT ID,
DBMS_ROWID.ROWID_RELATIVE_FNO(ROWID) FILE#,
DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID) BLOCK#
FROM SAMAD.TBL_CFTEST;
ID FILE# BLOCK#
---------- ---------- ----------
1 6 238
2 6 238
3 6 238
4 6 239
Another row on same block update on Node 2, and we see 4 CR copies and 1 XCUR copy.
SQL> UPDATE SAMAD.TBL_CFTEST SET NAME='Y' WHERE ID=3;
1 row updated.
SQL> @obj_buffer.sql
Enter value for objid: 93861
old 21: WHERE OBJD= &OBJID
new 21: WHERE OBJD= 93861
FILE# BLOCK# CLASS TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 238 DATA BLOCK cr 00
6 238 DATA BLOCK cr 00
6 238 DATA BLOCK cr 00
6 238 DATA BLOCK xcur 0000000087BE6448
6 238 DATA BLOCK cr 00
6 239 DATA BLOCK scur 0000000087BE00C0
6 239 DATA BLOCK cr 00
7 rows selected.
On node 1, previously updated record (LOCK_ELEMENT_ADD-> 00000000877E7C58) status changed to Past Image (PI) mode.
SQL> @obj_buffer.sql
Enter value for data_obj_id: 93861
old 9: where objd = &data_obj_id
new 9: where objd = 93861
FILE# BLOCK# CLASS_TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 238 data block pi 00000000877E7C58
6 238 data block cr 00
6 238 data block cr 00
6 238 data block cr 00
6 239 data block scur 00000000877E4490
5 rows selected.
Once made checkpoint, PI changed to CR.
SQL> alter system checkpoint;
System altered.
SQL> @obj_buffer.sql
Enter value for data_obj_id: 93861
old 9: where objd = &data_obj_id
new 9: where objd = 93861
FILE# BLOCK# CLASS_TYPE STATUS LOCK_ELEMENT_ADD
---------- ---------- ------------------ ---------- ----------------
6 238 data block cr 00
6 238 data block cr 00
6 238 data block cr 00
6 238 data block cr 00
6 239 data block scur 00000000877E4490
5 rows selected.
If we compare IO statistic, we see that more physical IO on Node 1 than Node 2. And “gc cr blocks received” value is 8.
Node 1: IO details
SQL> SELECT statistic_name, value
FROM v$segstat
WHERE dataobj# = &data_object_id and value > 0;
Enter value for data_object_id: 93861
old 3: WHERE dataobj# = &data_object_id and value > 0
new 3: WHERE dataobj# = 93861 and value > 0
STATISTIC_NAME VALUE
---------------------------------------------------------------- ----------
logical reads 80
db block changes 32
physical writes 8
physical write requests 4
space used 9257
space allocated 65536
6 rows selected.
Node 2: IO details
SQL> SELECT statistic_name, value
FROM v$segstat
WHERE dataobj# = &data_object_id and value > 0;
Enter value for data_object_id: 93861
old 3: WHERE dataobj# = &data_object_id and value > 0
new 3: WHERE dataobj# = 93861 and value > 0
STATISTIC_NAME VALUE
---------------------------------------------------------------- ----------
logical reads 48
db block changes 16
physical reads 6
physical writes 1
physical read requests 2
physical write requests 1
gc cr blocks received 8
gc current blocks received 1
8 rows selected.
[oracle@ocmnode2 ~]$ cat obj_stat.sql
SELECT statistic_name, value
FROM v$segstat
WHERE dataobj# = &data_object_id and value > 0
/
select s.name, st.value
from v$statname s, v$mystat st
where st.STATISTIC# = s.STATISTIC#
and s.name in ('session logical reads','physical reads');