12c Database : ASM Enhancements : New Failgroup Repair Time
When an transient disk failures happens the time to take to repair the offline disk from mirror groups will be set by diskgroup_repair_time.
For example, If diskgroup_repair_time is set as 3 hours and with in this period if disk repair is not completed, the ASM will drop the disks.
ASM keeps track of the changed extents that need to be applied to the offline disk. Once the disk is available, only the changed extents are written to resynchronize the disk, rather than overwriting the contents of the entire disk. This can speed up the resynchronization process considerably. This is called fast mirror resync.
Tricky question
Back to post,
What if total failgroup is having problem, Because failure group outages are more likely to be transient in nature and because replacing all the disks in a failure group is much more expensive operation than replacing a single disk, it would typically make sense for failure groups to have a larger repair time to ensure that all the disks does not get dropped automatically in the event of a failure group outage.
Hence from 12c onwards we have failgroup_repair_time which defaults to 24 hours (diskgroup_repair_time is 3.6 hours)
Quick example:-
#Pre requisite must be 11.1.0 or higher
SQL> select NAME ,COMPATIBILITY,DATABASE_COMPATIBILITY from v$asm_diskgroup where name='TEST_FAILGROUP';
NAME COMPATIBILITY DATABASE_COMPATIBILITY
TEST_FAILGROUP 11.1.0.0.0 11.1.0.0.0
SQL> create diskgroup test_failgroup
normal redundancy
failgroup A disk '/dev/sde2','/dev/sdh2'
failgroup B disk '/dev/sdb4','/dev/sdi1';
Diskgroup created.
## Tried to set this attribute on same diskgroup,
SQL> alter diskgroup test_failgroup set attribute 'failgroup_repair_time'='3H';
Diskgroup altered.
SQL> select group_number,name,value from v$asm_attribute where group_number=4 and name like 'failgroup%';
GROUP_NUMBER NAME VALUE
4 failgroup_repair_time 3H
12c Database : ASM Enhancements : OCR backup to disk group
Oracle Cluster Registry (OCR) backup in ASM disk group
Before to 12c the ocr backup is located in the master node local disk at GRID_HOME/cdata/backup, but if OCR is corrupted and you have to restore you will need to find the master node and initiate the restore option.
Storing the OCR backup in an Oracle ASM disk group simplifies OCR management by permitting access to the OCR backup from any node in the cluster should an OCR recovery become necessary.
Use ocrconfig command to specify an OCR backup location in an Oracle ASM disk group:
# ocrconfig –backuploc +DATA
12c Database : ASM Enhancements : Password files in ASM Disk group
ASM version 11.2 allowed ASM spfile to be placed in a disk group.
In 12c we can also put ASM password file in an ASM disk group.
Unlike ASM spfile, the access to the ASM password file is possible only after ASM startup and once the disk group containing the password is mounted.
The orapw utility now accepts ASM disk group as a password destination. The asmcmd has also been enhanced to allow ASM password management.
PWFILE=+DG1/Geek DBA12C/PASSWORD/pwracdb.464.327076728
12c Database : ASM Enhancements : Logical corruption checks on disk, disk scrubbing
ASM 12c provides proactive scrubbing capabilities on disks that check for logical corruptions and automatically repair them where possible.
SQL> alter diskgroup DG1 scrub repair;
Diskgroup altered.SQL> alter diskgroup DG1 scrub file '+DATA_DISK/Geek DBA12C/DATAFILE/system.254.939393617' repair wait;
Diskgroup altered.SQL> alter diskgroup DG1 scrub disk DATA_DISK1 repair power max force;
Diskgroup altered
REPAIR: If the repair option is not specified, ASM only check and report logical corruption
POWER: LOW, HIGH, or MAX. If power is not specified, the scrubbing power is controlled based on the system I/O load
FORCE: Command is processed immediately regarless of system load
Two ways of scrubbing: On-demand by administrator on specific area as like above, Occur as part of rebalance operation if disk attribute content.check=TRUE mentioned at disk level.
SQL> alter diskgroup DG1 attribute 'content.check' = 'TRUE';
Diskgroup altered.
-Thanks
12c Database : ASM Enhancements : New Replace Disk command
If an ASM disk becomes offline and cannot be repaired, administrators require the ability to replace the disk.
In prior versions of ASM, there was no replace command. Rather, administrators had to drop the faulty disk and then add a new one back into the disk group.
So,ASM level rebalance will takes place .Depending on multiple internal and external factor,reblance is time consuming.
In 12c ASM allows DBAs to simply replace an offline disk using one fast and efficient operation. There is no need for any additional reorganization or rebalancing across the rest of the disk group.
We now have a new ALTER DISKGROUP REPLACE DISK command, that is a mix of the rebalance and fast mirror resync functionality. Instead of a full rebalance, the new, replacement disk, is populated with data read from the surviving partner disks only. This effectively reduces the time to replace a failed disk.
Note that the disk being replaced must be in OFFLINE state. If the disk offline timer has expired, the disk is dropped, which initiates the rebalance. On a disk add, there will be another rebalance.
Few factors
> ASM diskgroup level attribute compatible.asm should be of 12.1.0.0 for this feature
> Replacing disk should bad in true sense , ASM will not replace online disk.
> The replacement disk takes the same name as the original disk and becomes part of the same failure group as the original disk.
> Then replacing good disk should be sized equal or greater than replacing bad disk.Else replace will fail.
Important Note: you cannot replace the disk that is smaller than failed disk size, if so you will face the followign issue.
ORA-15408: Replacement disk for 'FAILGROUP_0002' must be at least 2541 M.
12c Database : ASM Enhancements : Estimate the work for adding/deleting disks
Before 12C,we can only come know about estimate time of disk add/drop like expensive operation at diskgroup level. So,We could not predict how much time this will take in before hand .
In 12c ASM, a more detailed and more accurate work plan is created at the beginning of each rebalance operation.
In addition, DBAs can separately generate and view the work plan before performing a rebalance operation.
This allows DBA to better plan and execute various changes such as adding storage, removing storage or moving between different storage systems.
DBAs can generate the work plan using the ESTIMATE WORK command.
Querying from V$ASM_ESTIMATE view give an idea of required time of that operation based on current workload on the system. So,in while planning such operation ,DBAs needs to take consideration of system load and without running the original operation can make approximate
estimation of their operation at ASM level.
If you want to drop a disk from a diskgroup and if you specify wrong disk name ,then this will estimation will fail. Need to give proper disk name.
SQL> explain work set statement_id='drop_test_failgroup_0000' for alter diskgroup test_failgroup drop disk test_failgroup_0000;
Explained.SQL> select est_work from v$asm_estimate where statement_id='drop_test_failgroup_0000';
EST_WORK
----------
42
-Thanks
12c Database : ASM Enhancements : Physical Metadata Replication – Avoid header corruption cases
Prior to 12c the ASM metadata is stored in the disk header under allocation unit 0 AU0, if this unit is got corrupted in the disk the whole disk is not usable.
Since version 11.1.0.7, ASM keeps a copy of the disk header in the second last block of AU1. Interestingly, in version 12.1, ASM still keeps the copy of the disk header in AU1, which means that now every ASM disk will have three copies of the disk header block.
Starting 12c, the allocation unit AU0 is replicated to AU11 (Allocation unit 11) under same disk to ensure a copy of the metadata. (Ofcourse a disk failure cannot overcome this).
So you have metadata copy of disk in three allocation unit AU0, AU1, AU11.
To use this feature a new asm disk attribute must be set to 12.1.0.1.
Disk group attribute PHYS_META_REPLICATED
The status of the physical metadata replication can be checked by querying the disk group attribute PHYS_META_REPLICATED. Here is an example with the asmcmd command that shows how to check the replication status for disk group DATA:
Create a disk group with compatibile attribute 11.2
SQL> create diskgroup DG1 external redundancy disk '/dev/sdc1' attribute COMPATIBLE.ASM'='11.2';
Diskgroup created.
Check the replication status:
$ asmcmd lsattr -G DG1 -l phys_meta_replicated
Name Value
There is no value for the DG1
Let's check the diskgroup header using kfed for flags,
Note: flag = 0 no replication of disk header
flag = 1 replication
flag = 2 replication is in progress
$ kfed read /dev/sdc1 | egrep "type|dskname|grpname|flags"
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfdhdb.dskname: DG1_0000 ; 0x028: length=8
kfdhdb.grpname: DG1 ; 0x048: length=3
kfdhdb.flags: 0 ; 0x0fc: 0x00000000
As you see the 0 is set means no disk header replication.
Now lets change the attribute of disk to 12.1, this time use asmcmd rather alter disk group
$asmcmd setattr -G DG1 compatible.asm 12.1.0.0.0
$ asmcmd lsattr -G DG1 -l phys_meta_replicated
Name Value
phys_meta_replicated true
As you see now the disk group phs_meta_replicated showing true now,
Lets check at the disk header directly using kfed.
$ kfed read /dev/sdc1 | egrep "dskname|flags"
kfdhdb.dskname: DG1_0000 ; 0x028: length=8
kfdhdb.flags: 1 ; 0x0fc: 0x00000001
Flags set to 1 means the header is replication, the other status numbers are 0 which is not replicated and 2 means the header replication is in progress.
ASM version 12 replicates the physically addressed metadata, i.e. it keeps the copy of AU0 in AU11 - on the same disk. This allows ASM to automatically recover from damage to any data in AU0. Note that ASM will not be able to recover from loss of any other data in an external redundancy disk group. In a normal redundancy disk group, ASM will be able to recover from a loss of any data in one or more disks in a single failgroup. In a high redundancy disk group, ASM will be able to recover from a loss of any data in one or more disks in any two failgroups.
12c Database : ASM Enhancements : FlexASM – Overview
Flex ASM is a new architecture in Oracle Cluster/Grid Infrastructure where you can reduce the foot print of ASM instances in the cluster. I.e you really do not need 4 ASM instances for 4 Nodes.
In addition to above, Flex ASM also alleviate the problem of RDBMS instance dependency on ASM instance. For instance, if an ASM instance is down in a node , all of the rdbms instances in that node will fail and down.
To understand how this works. we just need to get some brief on leaf nodes and hub nodes.
In a clustered environment (Now oracle Flexcluster), Oracle now expands the capability of monitoring and managing the middleware layer through grid infrastructure i.e if you have oracle ebs instances as your middleware those also can be part of your cluster but having less priority those are called leaf nodes. Hub nodes in the contrast are high priority like RDBMS instances or ASM instances etc.
Coming back to the Flex ASM, asm disks can be mounted across this hub nodes for example a group of nodes called as a hub and managed by certain set of asm instances and so on with either a separate ASM private network or with private cluster interconnect. The ASM instances itself now acts as clients to its ASM instances in flex asm mode, as the one of the hub nodes really not running the asm instance rather connected as a client to other hub node and uses that asm instance remotely In order to achieve this, you will need to have special considerations on your RAC Cluster.
ASM network
With Flex ASM Oracle 12c, a new type of network is called the ASM network. it is used for communication between ASM and its clients and is accessible on all the nodes. All ASM clients in the cluster have access to one or ore ASM network. Also it is possible to configure single network can perform both function as a private and an ASM network
ASM Listeners
ADVM Proxy
See the installation screen shots while you install the Grid Infrastructure the ASM has new options
The first one is selection of ASM Network so that you can use seperate cluster network for ASM
The second one is selection of ASM flex storage option if this option is selected the Flex ASM option will be enabled and the ASM instances will not run on all instances and clients has direct access to the ASM storage by reading the metadata from other ASM instances.


Let's see practicaly what is it,
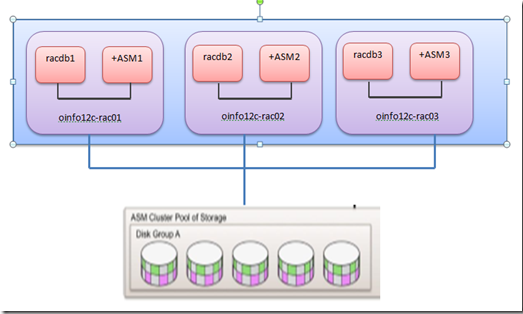
General Architecture - Non Flex ASM (i.e Standard ASM)

Let's set the cardinality to 2, means I want only 2 asm instances in my cluster, Means Enabling Flex ASM
#Enabling Flex ASM
General Architecture - Flex ASM

ASM : ASMCMD in 12c
New ASMCMD commands, now ASMCMD has the ability to do password file management, patches on asm instances, and version
and there are lots of changes new stuff in acfs command line tool
Let’s have look on New Features in Oracle 12c of ASMCMD. Below are the new features of Oracle 12c version.
1. Connecting to ASM instance of remote node:
Now we can connect to asmcmd prompt(asm instance) of remote node from local node.
SYNTAX – asmcmd –inst < REMOTE ASM INSTANCE NAME>
asmcmd --inst +ASM2
2.Move ASM password file using pwmove:
We can move the asm pwfile from one diskgroup to another diskgroup online using pwmove command.
Check the asm pwfile location
$ crsctl stat res ora.asm -p|grep PWFILE PWFILE=+MGMTDB/orapwASM $ crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4537: Cluster Ready Services is online CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online
Connect to asmcmd and run pwmove command
$echo $ORACLE_HOME $/crsapp/app/oracle/product/grid12c echo $ORACLE_SID +ASM1 $ asmcmd ASMCMD> pwmove --asm +MGMTDB/orapwASM +B2BWMDB/orapwASM moving +MGMTDB/orapwASM -> +B2BWMDB/orapwASM
Check the new location.
crsctl stat res ora.asm -p|grep PWFILE PWFILE=+B2BWMDB/orapwASM
Check the crs status:
$ crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4537: Cluster Ready Services is online CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online
We can see cluster components are online during the password movement activity.
3. Rebalance from asmcmd :
Now we can do rebalance of diskgroup from asmcmd prompt also.
To rebalance a diskgroup with power limit of 100
SYNTAX –
rebal –power < POWER_LIMIT> < DISKGROUP_NAME>
ASMCMD> rebal --power 100 B2BWMDB Rebal on progress.
To monitor the rebalance operation:
ASMCMD> lsop Group_Name Pass State Power EST_WORK EST_RATE EST_TIME B2BWMDB COMPACT WAIT 1 0 0 0 B2BWMDB REBALANCE RUN 1 12072 4400 2
4. Miscellaneous asmcmd commands:
Check the patches installed in grid home:
ASMCMD> showpatches
Check asm instance version:
ASMCMD> showversion
Check the cluster mode:
ASMCMD> showclustermode ASM cluster : Flex mode disabled
Check the cluster state:
ASMCMD> showclusterstate Normal

{kind=link}
{kind=link}
No comments:
Post a Comment