What is Oracle ASM

ASM Architecture
Operational Stack
- The concept of logical volumes / filesystems / and Oracle datafiles has been removed by ASM.
- This removal of the management area means that the obstacles are reduced that much, and the management cost can be dramatically reduced.
- Oracle ASM is a volume manager and a file system for Oracle database files.
- It supports single-instance and Oracle RAC configurations.
- Oracle ASM also supports a general purpose file system that can store application files and oracle database binaries.
- It provides an alternative to conventional volume managers, file systems and raw devices.
- Oracle ASM distributes I/O load across all available resource to optimize performance.
- In this way, it removes the need for manual I/O tuning (spreading out the database files avoids hotspots).
- Oracle ASM allows the DBA to define a pool of storage (disk groups).
- The Oracle kernel manages the file naming and placement of the database files on the storage pool.
• Oracle ASM Instances
• Oracle ASM Disk Groups
• Mirroring and Failure Groups
• Oracle ASM Disks
• Oracle ASM Allocation Units
• Oracle ASM Files
• Oracle ASM Striping
Oracle ASM Instances




Oracle ASM metadata
• The amount of space that is available in a disk group
• The file names of the files in a disk group
• The location of disk group data file extents
• A redo log that records information about atomically changing metadata blocks
• Oracle ADVM volume information and so on...
Oracle ASM Disk Group
Mirroring and Failure Groups
• High for 3-way mirroring (usable space = total space/3 ) Minimum disk needed 3
Oracle ASM Disks
• A disk or partition from a storage array
• An entire disk or the partitions of a disk
• Logical volumes
• Network-attached files (NFS)
Oracle ASM Allocation Units
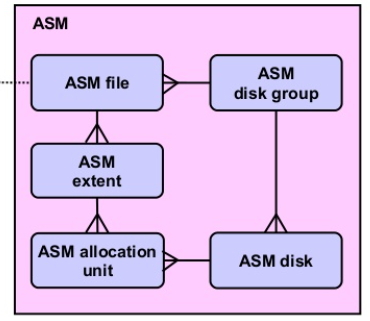
Oracle ASM Files
Oracle ASM Striping
Coarse-Grained Striping
Fine-Grained Striping
Key Benefits of ASM
- Simplifies and automates storage management
- Increases storage utilization and agility
- Delivers predictable performance, availability and scalability.
- Support database failure in the event of server crash.
- Integrated storage management with ACFS
Disk Group
- ASM disk group is a collection of disks managed as a logical unit, and is the best data structure considered in ASM. Each disk group contains its own file directory, disk directory, and other meta data.
- Oracle ASM store data files on disk groups.
- A disk group is a collection of disks managed as a unit by Oracle ASM.
- Oracle ASM disks can be defined on:
- A disk partition: Entire disk or a section of disk that does not include the partition table (or it will be overwritten).
- A Disk from a storage array (RAID): RAID present disks as Logical Unit Numbers (LUNs).
- A logical volume.
- A Network-attached file (NFS): Including files provided through Oracle Direct NFS (dNFS).Whole disks, partitions and LUNs can also be mounted by ASM through NFS.
- Load balance: Oracle ASM spreads the files proportionally across all of the disks in the disk group, so the disks within a disk group should be in different physical drives.
- Disks can be added or removed from a disk group while the database is accessing files on that disk group (without downtime).
- Oracle ASM redistributes contents automatically
- Oracle ASM uses Oracle Managed Files (OMF).
- Any Oracle ASM file is completely contained within a single disk group.
- However, a disk group might contain files belonging to several databases.
- A single database can use files from multiple disk groups.
- As extents proportional to the size of the disk are allocated to each disk, the I/O load generated by the application is evenly distributed to all disks belonging to one disk group. With this function, when there is no disk space in the disk group, it means that all disks are full of data.
Failure Group
- A failure group is a part of a disk group that shares storage resources. The 'resource' here refers to the resources shared by the disks that are affected together when a failure occurs. For example, if some disks are connected to SCSI controller 1 and the other disks are connected to SCSI controller 2, the former disks become Failure group 1, and the remaining disks belong to Failure group 2. In other words, the aggregate of disks with the same fate forms a failure group. As a result, one disk group can consist of multiple failure groups.
ASM Disk
- One disk group is composed of an aggregate of ASM disks. In other words, when storage is added or deleted from a disk group, it is processed in units of ASM disks. Also, it must be a physical disk capable of direct I/O from the database instance.
Allocation Unit (AU)
- Each ASM disk is divided into allocation units (AUs), which are the basic allocation units within a disk group. A file extent consists of one or more AUs, and an ASM file consists of one or more file extents.
- This AU is determined when creating a disk group and has a value of 1, 2, 4, 8, 16, 32, or 64 MB.
ASM Extents
Every ASM disk is divided into allocation units (au). ASM files are stored as extents and an extent consists of one or more allocation unit, though it was only 11g that brought in variable sized extents. The ASM instance provides the RDBMS instance with an extent map that the RDBMS instance then uses when doing I/O.

The diagram above is meant to show the extents of a pair of ASM files distributed amongst the available drives in a disk group. Essentially this is the algorithm that ASM uses to maximise the I/O performance – spread all data across the disks in a disk group.
When you create a disk group in 11g you can specify the size of the allocation unit to be from 1MB to 64MB, the size doubling between these limits. That is you can set the size of the au for a disk group to be one of 1, 2, 4, 8, 16, 32, or 64MB.
Clearly the larger the au size chosen the less the number of extents it will take to map a file of a given size. The larger au are clearly beneficial for large data files and cuts down on SGA required to track. Each individual extent resides on a single disk.
Extents can vary in size from 1 au to 8 au to 64 au. The number of au a given extent will use is dependent on the number of extents allocated and the extent size increases at a threshold of 20,000 extents to 8 and then again at 40,000 extents to 64. Again this is designed to be beneficial to larger data files, requiring less extents to be tracked.
You can see how the extents are allocated between disks in a disk group by looking at the X$KFFXP view:
SQL> select count(*), group_kffxp, disk_kffxpfrom X$KFFXP
group by group_kffxp, disk_kffxp
order by group_kffxp;
This will show you how many au have been allocated to each disk, if you have a healthy balanced system each disk in a disk group should have a similar number of au.
A very useful script for looking at all this is available on metalink, look for Note: 351117.1, diagnosing ASM space issues, well worth having a look at.
| Mirroring and Failure groups |
- Disk groups can be configured with varying redundancy levels.
- For each disk in a disk group, you need to specify a failure group to which the disk will belong.
- A failure group is a subset of the disks in a disk group, which could fail at the same time because they share hardware
- Failure groups are used to store mirror copies of data.
- In a normal redundancy file, Oracle ASM allocates a primary copy and a secondary copy in disks belonging to different failure groups.
- Each copy is on a disk in a different failure group so that the simultaneous failure of all disks in a failure group does not result in data loss.
- A normal redundancy disk group must contain at least two failure groups.
- Splitting the various disks in a disk group across failure groups allows Oracle ASM to implment file mirroring.
- Oracle ASM implements mirroring by allocating file and file copies to different failure groups.
- If you do not explicitly identify failure groups, Oracle allocates each disk in a disk group to its own failure group.
Oracle ASM implements one of three redundancy levels:
|
ASM Rebalancing & ASM Mirroring
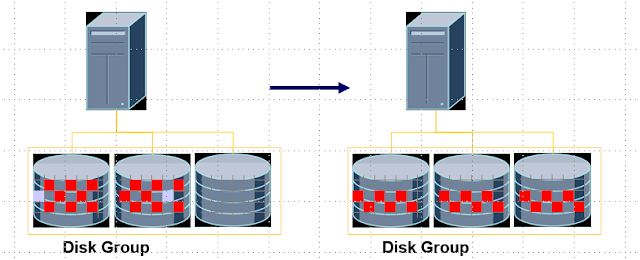
ASM Rebalancing
- When disks are added/deleted or resized, the disk group performs rebalancing to equalize the load on all storage. The operation is performed based on the size of the disk included in the disk group.
- This operation is automatically performed when storage configuration information is changed, and can be manually generated by the DBA.

ASM Mirroring
- Provides database-level software mirroring.
- The following 3 methods are provided.
- External : When you want to use hardware mirroring
- Normal (2-way): A configuration in which a specific ASM disk group has at least two failure groups
- High (3-way): A configuration in which a specific ASM disk group has at least 3 failure groups
- A copy of EXTENT of ASM Disk is saved/maintained in another failure group. For this reason, the hot spare disk used in the traditional Hardware Mirroring is not required, all you need is an additional disk capacity to keep the copy EXTENT.

ASM Diskgroup
Once an ASM disk is discovered, it can be used to create ASM diskgroups that are used to store the file systems for Clusterware and the database files and ACFS Oracle home. Every Oracle ASM diskgroup is divided into allocation units (AU), the sizes of which are determined by the AU_SIZE disk group attribute. The AU_SIZE can be 1, 2, 4, 8, 16, 32, or 64 MB. Files that are stored in an ASM diskgroup are separated into stripes and evenly spread across all the disks in the diskgroup. This striping aims to balance loads across all the disks in the disk group and reduce I/O latency. Every ASM disk that participates in striping should have the same disk capacity and performance characteristics. There are two types of striping: coarse striping and fine striping. The coarse striping size depends on the size of the AU; it is used for most files, including database files, backup sets, etc. The fine striping is used for control files, online redo logs, and flash back logs. The stripe size is 128 KB.
The failure group concept was introduced to define a subset of disks in a diskgroup that could fail at the same time; for example, disks in the same failure group could be linked to the same storage controller. If we mirror the storage in an ASM diskgroup, we want to make sure to put the mirroring copies on the disks in different failure groups to avoid losing all the mirroring copies at the same time.
ASM provides three types of redundancy for ASM diskgroup:
The ASM files are striped across all the disks of the diskgroup.

Normal Redundancy:

High Redundancy:Oracle

- An Oracle ASM disk is divided into allocation units (AU).
- Files within an ASM disk consist of one or more allocation units.
- Each ASM file has one or more extents.
- Extent size is not fixed: starting with one allocation unit, extent size increases as total file size increases.
Relationship between ASM AU Size, ASM File Extents and ASM stripe size
The ASM AU Size , also known as the ASM allocation unit size, is the size of each basic storage allocation per disk in a particular diskgroup and these storage allocations are defined at the disk group creation time. Each of these storage allocations or allocation units hold either an entire file extent or a part of a file extent depending on whether or not the number of file extents in the file exceed a threshold.
The default size of an AU is 1M. A different value can be selected at diskgroup creation time.
File Extents are the basic units in terms of how ASM stores data across the disks in a disk group. Every disk in a diskgroup is designed to have the same number of file extents.
And also, when ASM mirroring used, it is the file extents that get mirrored across the various failure groups.
By default, the file extent size is equal to 1 AU size. So in the simplest case, when the number of file extents in a file is less than 19999, each allocation unit will hold one file extent.
File extents are exposed in x$kffxp.
File extent sizes can be a multiple of the AU size, which happens when the file size becomes greater than a threhhold value. If the file size becomes greater than or equal to 20000AUs, then each file extent will be comprised of 4 AUs and when the file size becomes equal to or exceeds 40000 AUs, the file extent size becomes 16*AU size (each file extent will be comprised of 16 AUs).
And when this happens, the entire file extent will be spread across the 4 or 8 allocation units it in the same disk.
Below is a sample output showing a file extent distribution in a diskgroup created with normal redundancy, comprising of 2 failure groups with 3 disks in each failure group.
The file size is 21G in size and the AU size of the diskgroup is 1M. It belongs to a tablespace called TASSM2.
SQL> select
file_name,bytes/1024 sz from dba_data_files where tablespace_name=‘TASSM2’
FILE_NAME SZ
———————————————————————-
———-
+TESTVD/db11203g/datafile/tassm2.258.818522513 22020096
Total: 22020096
So the file_number of the file is 258 and the diskgroup where it resides is called +TESTVD.
select
size_kffxp, ======> The size of the File Extent in
terms of the number of allocation units. Jumps to 4 whenxnum_kffxp crosses
19999
disk_kffxp, ======> The disk number
au_kffxp, ======> The allocation unit (AU) number
NUMBER_KFFXP, ======> The File Number
pxn_kffxp, ======> Unique File Extent number
.Increases for both primary and mirrored extents.
lxn_kffxp, ======> Identifier to identify primary
extents versus mirrored extents. 0 -> primary.
xnum_kffxp =====> The “true” File Extent number
.Does not increase for mirrored extents.
from x$kffxp
where group_kffxp=7 =====> The group number for the +TESTVD
diskgroup is 7
and number_kffxp=258
order by 8;

The highlighted line above shows how the size of the file extent changes to 4 AUs when the number of file extents exceeds 19999. It is also seen that the 4 AUs, needed by each of the file extents from file extent# 20000 upwards, is indeed taken from the same disk.
So for file extent number 20000, we see all the 4 AUs are taken consecutively from disk# 0. And these AUs are 27820,27821,27822,27823. If this was not the case and if the 4 consecutive AUs did not belong to File extent# 20000, then AU# 27821 should have belonged to a different file extent .And this would have meant, we would have seen a record for AU_KFFXP=27821 in the same file and same disk i.e. (NUMBER_KFFXP=258 and DISK_KFFXP=0), because x$kffxp has a record for every unique file extent (xnum_kffxp).
So do we see a record for AU_KFFXP=27821 and NUMBER_KFFXP=258 and DISK_KFFXP=0 ?
select count(*) from x$kffxp where group_kffxp=7 and number_kffxp=258 and au_KFFXP=27821 and DISK_KFFXP=0
00:51:48 +ASM1> /
COUNT(*)
———-
0 ===> The answer as expected is NO.
In fact, as seen in the second highlighted line above, the next file extent in disk# 0 for the file (file# 258) is 20003 and starts at AU# 27824. This is what we expect as well, since AU numbers 27820-27823 is taken by File extent# 20000. This further confirms the theory.
Stripe size is the chunk size of data that will be written to each disk in a round robin fashion.
As we know, we can either fine grained striping or coarse grained striping.
Fine grained striping stripes at 128K and coarse grained striping stripes at 1M.
Based on that we can have the cases below:
- If the stripe size is 128K (file grained striping), each file extent, which would be a minimum of 1M (case where AU size = 1M and #of file extents <20000), will be written to in chunks of 128K in a round robin fashion across all the disks in the diskgroup. This will mean, when a write of say 1M is issued, the 1M write will be divided into 8 chunks of 128K each and each of these 128K chunks will be written to one file extent of all the disks in a round robin fashion. Once all the disks are written to with 128K chunks, writing begins again at the first disk’s extent where it started, since that file extent being 1M at a minimum, still has at least (1024K – 128K = 896K) left.
- For a stripe size of 1M (coarse grained striping), for a file with up to 19999 extents, the stripe size will match the AU size and the file extent size. So in this case, things will be simple in that each AU will exactly hold one file extent which in turn will exactly hold one stripe.
- And in the other case of coarse grained striping, when the file has more than 19999 extents, (when the file extent size becomes 4 or 8 times an AU), each file extent will be comprised of 4 to 8 allocation units. And then when a write is issued, the amount of data to be written will be broken up into chunks of 1M and each of these 1M chunks will be written to one file extent of all the disks in a round robin fashion, much like the case of fine grained striping described in case A, with the difference with case A and here being the fact that the stripe size here is 1M instead of 128K and the file extent size here being 4M or 8M instead of 1M (assuming an AU size of 1M). The point of similarity though with case A and here being the fact that in both the cases, the file extent size is more than the stripe size.
We can represent the ASM striping diagrammatically as below. The members refer to individual disks inside the diskgroup:

| Oracle ASM Instance |
Oracle ASM metadata:
|
- With Oracle ASM an ASM instance besides the database instance needs to be configured on the server.
- An Oracle ASM instance has an SGA and background processes, but is usually much smaller than a database instance.
- It has minimal (how much?) performance effect on a server.
- Oracle ASM Instances are responsible for mounting the disk groups so that ASM files are available for DB instances.
- Oracle ASM instances DO NOT mount databases.
- They only manage the metadata of the disk group and provide file layout information to the database instances.

- One Oracle ASM instance in each cluster node.
- All database instances in a node share the same ASM instance
- In a Oracle RAC environment, the ASM and database instances on the surviving nodes automatically recover from an ASM Instance failure on a node.








No comments:
Post a Comment