I am going to share the most common wait events in the Oracle database, as I have observed that many Oracle DBAs are not aware of these events and struggle to explain them during interviews.
I hope this post will help those who have difficulty identifying common wait events, understanding how to find them, and knowing how to resolve them in the Oracle database.
In my previous post, I explained Wait Classes and Wait Events.
Let's get started!
Wait events are statistics that a server process or thread increments when it waits for an operation to complete in order to continue its processing.
For example, a SQL statement may be modifying data, but the server process may have to wait for a data block to be read from disk because it’s not available in the SGA.
Information about wait events is displayed in three dynamic performance views:
V$SESSION_WAITdisplays the events for which sessions have just completed waiting or are currently waiting.V$SYSTEM_EVENTdisplays the total number of times all the sessions have waited for the events in that view.V$SESSION_EVENTis similar toV$SYSTEM_EVENT, but displays all waits for each session.
Although there’s a large number of wait events, some the most common wait events are the following:
==========================================================
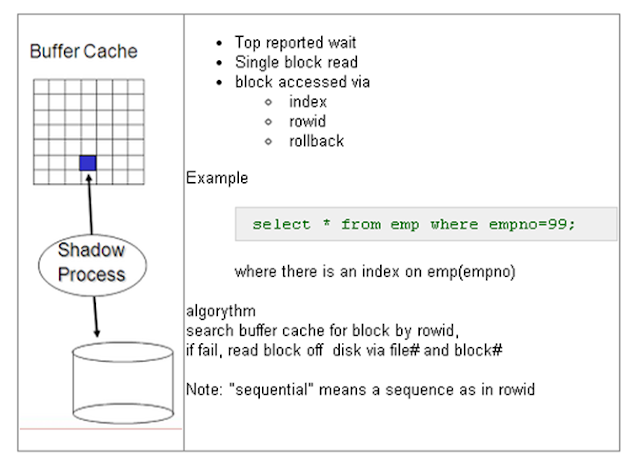
1) db file sequential read :
Wait Class : User I/O
Db file sequential reads wait event occurs when a process has issued an I/O request to read one block (single block I/O) from a datafile (Or datafile headers) into the buffer cache and is waiting for the operation to complete.
These single block I/Os are usually a result of using
indexes Or table data blocks accessed through an index.
So, when you issue any SQL Statement that performs a single block read operation against indexes, undo segments, tables (only when accessed by rowid), control files and data file headers, oracle server process waits for the OS to provide that block from the data file, and the wait event on which server process waits till the block is made available is termed as db file sequential read
Description: This wait event typically occurs when a session is performing a query or operation that requires fetching data from a single data block in a datafile, such as a table or index block.
Cause: It occurs when the requested data block is not currently in the database buffer cache (the portion of the memory used to store data blocks), so Oracle needs to read the block from disk into the buffer cache before the session can proceed with the operation
Possible Causes :
· Use of an unselective index
· Fragmented Indexes
· High I/O on a particular disk or mount point
· Bad application design
· Index reads performance can be affected by slow I/O subsystem and/or poor database files layout, which result in a higher average wait time.
Scenario:
For example, when a user executes a query that involves scanning an index or fetching rows from a table, and the required data block(s) are not already in memory, Oracle has to perform a physical I/O operation to read the block(s) from disk into memory. During this time, the session is in a "db file sequential read" wait state.
Here are some SQL examples that may increase "db file sequential read":
1. Full Table Scan:
SELECT * FROM your_table;
Running a full table scan on a large table may trigger "db file sequential read" waits, especially if the blocks needed for the scan are not already in the buffer cache.
2. Index Range Scan:
SELECT * FROM your_table WHERE indexed_column = some_value;
If the indexed column has a high cardinality and the index is not already in memory, performing an index range scan may result in "db file sequential read" waits.
3. Join Operations:
SELECT t1.column1, t2.column2 FROM table1 t1 JOIN table2 t2 ON t1.join_column = t2.join_column;
Join operations that involve fetching data from multiple tables may lead to "db file sequential read" waits if the required blocks are not already cached.
4. Sorting Operations:
SELECT * FROM your_table ORDER BY indexed_column;
Sorting large result sets may trigger "db file sequential read" waits if the sorted data needs to be read from disk.
5. Queries with Aggregation:
SELECT aggregated_column, COUNT(*) FROM your_table GROUP BY aggregated_column;
Aggregation operations that involve scanning large amounts of data may result in "db file sequential read" waits.
1) Optimizing SQL queries to minimize I/O operations,
2) Tuning disk I/O performance,
3) Increasing the size of the database buffer cache, or
4) Implementing appropriate indexing strategies to reduce disk I/O.
Below Actions can be taken :
· Check indexes on the table to ensure that the right index is being used
· Check the column order of the index with the WHERE clause of the Top SQL statements
· Rebuild indexes with a high clustering factor
· Use partitioning to reduce the amount of blocks being visited
· Make sure optimizer statistics are up to date
· Relocate ‘hot’ datafiles
· Consider the usage of multiple buffer pools and cache frequently used indexes/tables in the KEEP pool
· Inspect the execution plans of the SQL statements that access data through indexes
· Is it appropriate for the SQL statements to access data through index lookups?
· Would full table scans be more efficient?
· Do the statements use the right driving table?
· The optimization goal is to minimize both the number of logical and physical I/Os.
There are following things that we can do:-
- Identify Top SQLs responsible for Physical Reads (SQL Ordered by Reads section in AWR) and tune them to use efficient explain plan:-
- If Index Range scans are involved, more blocks than necessary could be being visited if the index is unselective. By forcing or enabling the use of a more selective index, we can access the same table data by visiting fewer index blocks (and doing fewer physical I/Os).
- If indexes are fragmented, again we have to visit more blocks because there is less index data per block.
- In this case, rebuilding the index will compact its contents into fewer blocks. Indexes can be (online) rebuilt, shrunk, or coalesced.
- If the index being used has a large Clustering Factor, then more table data blocks have to be visited in order to get the rows in each index block: by rebuilding the table with its rows sorted by the particular index columns we can reduce the Clustering Factor and hence the number of table data blocks that we have to visit for each index block.
- Use Partitioning to reduce the number of index and table data blocks to be visited for each SQL statement by usage of Partition Pruning.
- Identify HOT Tablespace/Files which are are servicing most of the I/O requests.
- I/Os on particular datafiles may be being serviced slower due to excessive activity on their disks. In this case, find such hot disks and spread out the I/O by manually moving datafiles to other storage or by making use of Striping, RAID and other technologies to automatically perform I/O load balancing for us.
- Analyze V$SEGMENT_STATISTICS and see if indexes should be rebuilt or Partitioning could be used to reduce I/O on them.
- Use Buffer Cache Advisory and Increase the Buffer Cache if there is a potential benefit.
2. db_file _scatter_read ----> wait event
in oracle

Waits for multiple blocks (up to DB_FILE_MULTIBLOCK_READ_COUNT) to be read from disk while performing full table scans / Index fast full scans (no order by) . This wait is encountered because:
- Since a large no. of blocks have to be read into the buffer cache, server process has to search for a large no. of free/usable blocks in buffer cache which leads to waits.
This wait happens when a session is
waiting for a multiblock IO to complete. This typically occurs during full
table scans or index fast full scans. Oracle reads up to
DB_FILE_MULTIBLOCK_READ_COUNT consecutive blocks at a time and scatters them
into buffers in the buffer cache.
Possible Causes :
· The Oracle session has requested and is waiting for multiple contiguous
database blocks (up to DB_FILE_MULTIBLOCK_READ_COUNT) to be read
into the SGA from disk.
· Full Table scans
· Fast Full Index Scans
Actions :
· Optimize multi-block I/O by setting the parameter
DB_FILE_MULTIBLOCK_READ_COUNT
· Partition pruning to reduce number of blocks visited
· Consider the usage of multiple buffer pools and cache frequently
used indexes/tables in the KEEP pool
· Optimize the SQL statement that initiated most of the waits. The goal is
to minimize the number of physical
and logical reads.
· Should the statement access the data by a full table scan or index FFS?
Would an index range or unique scan
be more efficient? Does the query use the right driving table?
· Are the SQL predicates appropriate for hash or merge join?
· If full scans are appropriate, can parallel query improve the
response time?
· The objective is to reduce the demands for both the logical and physical
I/Os, and this is best
achieved through SQL and application tuning.
· Make sure all statistics are representative of the actual data. Check
the LAST_ANALYZED date
Remarks:
· If an application that has been running fine for a while suddenly clocks
a lot of time on the db file scattered read event and there hasn’t been a code
change, you might want to check to see if one or more indexes has been dropped
or become unusable.
· Or whether the stats has been stale.
Solutions :
- Try to cache frequently used small tables to avoid
readingthem into memory over and overagain.
- Optimize multi-block I/O by setting the parameter
DB_FILE_MULTIBLOCK_READ_COUNT
- Partition pruning: Partition tables/indexes so that
only a partition is scanned.
- Consider the usage of multiple buffer pools
- Optimize the SQL statement that initiated most of the
waits. The goal is to minimize the number of physical and logical reads.
. Should the statement access the
data by a full table scan or index FFS?
. Would an index range or unique scan
be more efficient?
. Does the query use the right
driving table?
. Are the SQL predicates appropriate
for hash or merge join?
. If full scans are appropriate, can
parallel query improve the response time?
- Make sure all statistics are representative of the
actual data. Check the LAST_ANALYZED date
Common Causes and Actions:-
It is common for full table scans or index fast full scans operations to
wait on physical I/Os to complete.
The DBA should not be alarmed just because this event shows up in the database.
Rather, the DBA should be concerned with the average I/O time and sessions that
spend a lot of time on this event.
The average multi-block I/O wait should not exceed 1 centisecond (1/100
second).
If the db file scattered read is costly, this could indicate the storage
subsystem is slow or the database files are poorly placed.
The DBA should ensure that the system is properly configured.
Follow the suggestions in the db file sequential read event section.
- If the average I/O wait time for the db file scattered read event is acceptable, but the event represents a significant portion of waits in a certain session, then this is an application issue.
- In this case, the DBA needs to determine which object is being read the most from the P1 and P2 values, extract the relevant SQL statement, generate and examine the explain plan against the SQL predicates, and advise on tuning.
- Should the statement use full table scan/index FFS to access data?
- Would an index access be more efficient?
- Does the query use the right driving table?
- The objective is to reduce both the logical and physical I/O calls, and this can be best achieved through SQL and application tuning.
- SQL plans that join tables using HASH JOIN or SORT MERGE operation, scan the tables, and I/O waits show up as db file scattered read events. In this case, the DBA also needs to evaluate the SQL predicates and determine if the HASH JOIN or SORT MERGE is appropriate.
- If an application that has been running fine for a while suddenly clocks a lot of time on the db file scattered read event and there is no code change, then this is certainly an index issue.
- One or more indexes may have been dropped or become unusable.
- To determine which indexes have been dropped, the DBA can compare the development, test, and production databases.
- The ALTER TABLE MOVE command marks all indexes associated with the table as unusable.
- Certain partitioning operations can also cause indexes to be marked unusable. This includes adding a new partition or coalescing partitions in a hash-partitioned table, dropping a partition from a partitioned table or global partitioned index, modifying partition attributes, and merging, moving, splitting or truncating table partitions.
- A direct load operation that fails also leaves indexes in an unusable state. This can easily be fixed by rebuilding the indexes.
- A DBA may have increased the value of the DB_FILE_MULTIBLOCK_READ_COUNT INIT.ORA parameter.
- The optimizer is more likely to choose a full table scan over an index access if the value of this parameter is high. Likewise, the HASH_AREA_SIZE and OPTIMIZER_INDEX_COST_ADJ parameters, when increased can skew the optimizer toward the full table scans. Make appropriate adjustments to these parameters so they do not adversely affect application runtimes.
- Out-of-date statistics are yet another factor that can adversely affect the quality of execution plans causing excessive I/Os. Keep all object statistics up to date.
- Note: The ANALYZE TABLE command with the COMPUTE option normally
performs full table scans and will add to the db file scattered read statistics
for the session (V$SESSION_EVENT) and instance (V$SYSTEM_EVENT).
- Tables with a non-default degree of parallelism also tend to move the optimizer in the way of full table scans. This, however, shows up as the direct path read event. Make sure the degrees of parallelism for tables are properly set.
Please find the below diagram to understand "db file sequential read" and "db file scatter read" :-

3. read by other session ----> wait event in oracle
When a user issues a query in an Oracle database, the Oracle server processes read database blocks from disk into the database buffer cache. If multiple sessions issue the same or related queries (accessing the same database blocks), the first session reads the data from the database buffer cache, while other sessions wait for access.

Resolving “buffer busy waits” events can be challenging. In I/O-bound Oracle systems, these waits are common, often surfacing in the top-five wait events alongside read by other session and buffer busy wait events. In essence, concurrent sessions reading the same blocks, table, or index blocks can create contention.
Identifying Block Contention
You can find block contention in AWR or Statspack reports, where common wait events like read by other session or buffer busy waits may appear among the top five. Additionally, the wait events section provides further details.
To query specific blocks experiencing contention, use:
To analyze buffer busy waits in more detail, consult v$segment_statistics or v$system_event.
Tuning the read by other session Wait Event
Hot Objects and Hot Blocks
Concurrent sessions accessing the same block in an object are known as hot objects. AWR’s Segment Statistics section can identify these hot objects, or you can use the query:
Causes of buffer busy waits/read by other session Events and Their Solutions
Increasing INITRANS:
Each database block has an ITL (Interested Transaction List) slot for concurrent DML transactions. TheINITRANSparameter sets the initial number of ITL slots per block (1 for table segments, 2 for index segments, and the defaultMAXTRANSis 255). If no ITL slots are free, transactions queue up. IncreasingINITRANScan prevent serialization and allow more concurrent DML operations on the same block. Each ITL requires ~23 bytes in the block header.Increasing PCTFREE:
Reducing the number of rows per block helps reduce contention. For example, increasing thePCTFREEvalue (default 10%) to 20% in an 8 KB block means fewer rows can be inserted per block.PCTFREEreserves space for future updates, and more free space reduces the likelihood of contention.Reducing Database Block Size:
Lowering the block size, similar to thePCTFREEadjustment, reduces rows stored per block. For example, splitting an 8 KB block (containing 1000 rows) into two 4 KB blocks halves the rows per block. In Oracle 9i and newer, place hot objects in a tablespace with a smaller block size.Tuning Inefficient Queries:
Reducing the number of blocks accessed by optimizing queries minimizes the blocks read from disk into the buffer cache. For example, adding indexes on a large table avoids full table scans, reducing blocks read from disk.
Conclusion
Optimize Inefficient Queries
Ensure execution plans minimize block reads. Adjust SQL to reduce both logical and physical reads.Adjust PCTFREE and PCTUSED
ModifyingPCTFREEfor fewer rows per block and adjustingPCTUSEDto control freelist behavior can help balance data distribution across blocks, reducing contention. Also, consider increasing FREELISTS and FREELIST GROUPS to distribute data more evenly and prevent hot blocks.Reduce Block Size
Storing hot objects in smaller blocks or tablespaces (post-Oracle 9i) helps reduce data density per block.Optimize Indexes
Low-cardinality indexes (few unique values) can lead to excessive reads and cache churn. Optimize these indexes to reduce contention.
Log File Sync Wait Event Explained
When a user session issues a commit, Oracle must make sure the transaction's redo information is permanently recorded in the redo log files.
When a user commits a transaction, Oracle must ensure the transaction's redo data (changes) is permanently saved to disk.
This is done by writing the redo information from memory (log buffer) to the redo log file on disk.
The user session requests the Log Writer (LGWR) process to perform this write.
While LGWR writes the data to the redo log file, the user session waits.
This waiting time is recorded as the log file sync wait event.
Here’s how this process works and the factors influencing performance:
Commit Process and Log File Sync Event
- Commit Initiation:
- When a user session commits, it triggers the LGWR (Log Writer) process to write all unwritten redo from the log buffer (including the current session’s redo) to the redo log file.
- Session Waits on LGWR:
- While LGWR writes the redo data to disk, the user session waits on a log file sync event. This ensures that all redo changes are safely recorded in the redo log file, safeguarding data integrity before the commit is finalized.
- Completion and Notification:
- After LGWR completes the write to the redo log, it posts back to the session, confirming that the commit is complete.
The log file sync wait time reflects the duration between when the session requests LGWR to flush redo to disk and when LGWR notifies the session that the write has finished. High wait times in log file sync can indicate delays in redo log writes, impacting transaction performance.
Common Causes of log file sync Wait Events
Slow Disk I/O Throughput:
- Cause: If the storage hosting redo logs is slow or has high latency, LGWR’s write operations take longer, increasing
log file syncwait times. - Solution: Use fast, low-latency storage for redo logs (e.g., SSDs) and consider dedicating separate disks for redo logs to improve write performance.
- Cause: If the storage hosting redo logs is slow or has high latency, LGWR’s write operations take longer, increasing
Excessive Application Commits:
- Cause: Frequent commits force LGWR to flush redo entries to disk more often, increasing the overall wait time for
log file sync. - Solution: Minimize unnecessary commits within applications. Batch multiple transactions in a single commit if possible, which reduces the frequency of LGWR writes.
- Cause: Frequent commits force LGWR to flush redo entries to disk more often, increasing the overall wait time for
Increasing Redo Log File Size:
- Benefit: Larger redo log files reduce the number of log switches, which can decrease I/O contention and improve performance, especially in environments with high transaction rates.
- Implementation: Monitor log switch frequency and adjust redo log file size accordingly, aiming for switches every 20-30 minutes under peak load.
Separating REDO Logs from Data and TEMP Files:
- Cause: Placing redo logs on the same disk as data files, TEMP files, or SYSTEM files can lead to I/O contention, slowing down LGWR writes.
- Solution: Place redo log files on a separate disk to balance the I/O load and improve write speeds.
Adjusting the Redo Log Buffer Size:
- Impact of Oversizing: If the redo buffer is too large, each commit forces LGWR to write a substantial amount of redo data, prolonging
log file syncwaits. - Impact of Undersizing: If redo buffer space is insufficient (
log buffer spacewaits are high), increasing the buffer size can help. Conversely, iflog file syncwaits are high, reducing buffer size can prompt LGWR to write more frequently with smaller data chunks. - Optimization: Use continuous monitoring to tune the redo buffer size based on workload, ensuring an appropriate balance between buffer size and write performance.
5. enq: TX - row lock contention ----> wait event in oracle
enq: TX - row lock contention wait event in Oracle signifies that a session is waiting to acquire a lock on a row in a table because another session has already locked it. This commonly occurs when multiple sessions try to modify the same row simultaneously or when there are uncommitted transactions.
Short Explanation : This type of contention typically happens in situations where two or more sessions are trying to modify the same row in a table and one session must wait until the lock held by another session is released.
Here's a more detailed breakdown:
What Causes enq: TX - row lock contention?
- Uncommitted Transactions: If a session modifies a row and doesn’t commit the transaction, other sessions trying to modify the same row have to wait.
- Primary Key or Unique Constraints: When multiple sessions attempt to insert rows with duplicate primary or unique keys, they may get blocked, causing row lock contention.
- Foreign Key Constraints: If a session is deleting or updating rows referenced by a foreign key without the proper indexes, it can cause contention for the TX lock.
- High Concurrent Updates: When many sessions are attempting to update the same set of rows, particularly in a high-contention table, row lock contention is more likely.
- Application Logic: Poor application design that serializes updates on specific rows can create bottlenecks and increase contention.
How to Identify enq: TX - row lock contention
To identify row lock contention, you can:
- Check for active sessions waiting on
enq: TX - row lock contentionusing thev$sessionview: - Use AWR or ASH reports to see if
enq: TX - row lock contentionappears frequently in the top wait events.
Resolving enq: TX - row lock contention
- Commit or Roll Back Unfinished Transactions: Ensure sessions commit or roll back transactions promptly to release row locks.
- Optimize Unique Constraints: Avoid duplicate key violations, and ensure application logic prevents them.
- Index Foreign Keys: Index columns involved in foreign key relationships to reduce locking issues.
- Reduce Contention on Hot Rows: If a specific row is being accessed too frequently, consider partitioning the table or modifying application logic to reduce concurrent access.
- Optimize Application Logic: Ensure the application avoids serializing updates or accessing the same rows at the same time unnecessarily.
Resolving Row Lock Contention:
- Identify Blocking Session: Use Oracle views like
V$SESSION,V$LOCKandV$TRANSACTIONto identify the session holding the lock and what it is doing. - Review Application Logic: Ensure that the application is designed to minimize row lock contention, such as reducing the frequency of updates on the same rows.
- Commit or Rollback Transactions Promptly: Encourage quick commits or rollbacks to reduce the duration for which locks are held.
Example Scenario
Imagine two sessions try to update the same row in a table.
The first session locks the row, but the second session must wait, causing the enq: TX - row lock contention event.
Once the first session commits or rolls back, the second session can acquire the lock and proceed with its transaction.
enq: TM – contention wait event indicates that there are unindexed foreign key constraints and this wait event is seen during DML on tables with unindexed foreign key.
Oracle locks the table if a DML is made to the main table with the primary key.
To solve this problem, you need to create the indexes for the non-indexed foreign key as follows.
executed statements similar to what
we found at this customer:
User 1: DELETE supplier WHERE supplier_id = 1;
User 2: DELETE supplier WHERE supplier_id = 2;
User 3: INSERT INTO supplier VALUES (5, 'Supplier 5',
'Contact 5');
User 1:-

User 2 :-

User 3:-



Similar to the customer's experience, User 1 and User 2 hung waiting on "enq: TM - contention".
Reviewing information from V$SESSION
I found the following:
FROM v$lock l, dba_objects o, v$session s
WHERE UPPER(s.username) = UPPER('&User')
AND l.id1 = o.object_id (+)
AND l.sid = s.sid
ORDER BY sid, type;

Sample
query to find unindexed foreign key constraints
Now that we know unindexed foreign
key constraints can cause severe problems, here is a script that I use to find
them for a specific user (this can easily be tailored to search all schemas):
SELECT c.table_name, cc.column_name, cc.position column_position
FROM user_constraints c, user_cons_columns cc
WHERE c.constraint_name = cc.constraint_name
AND c.constraint_type = 'R'
MINUS
SELECT i.table_name, ic.column_name, ic.column_position
FROM user_indexes i, user_ind_columns ic
WHERE i.index_name = ic.index_name
)
ORDER BY table_name, column_position;

Following along with the solution we
used for our customer, we added an index for the foreign key constraint on the
SUPPLIER table back to the PRODUCT table:
SQL> CREATE INDEX fk_supplier ON product (supplier_id);
When we ran the test case again everything worked fine. There were no exclusive locks acquired and hence no hanging.
Oracle takes out exclusive locks on the child table, the PRODUCT table
in our example, when a foreign key constraint is not indexed.


No comments:
Post a Comment